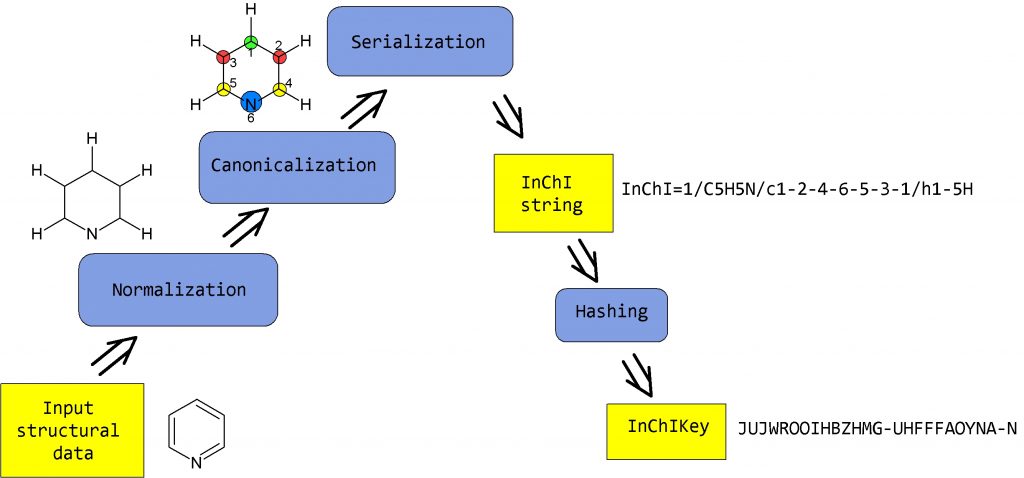
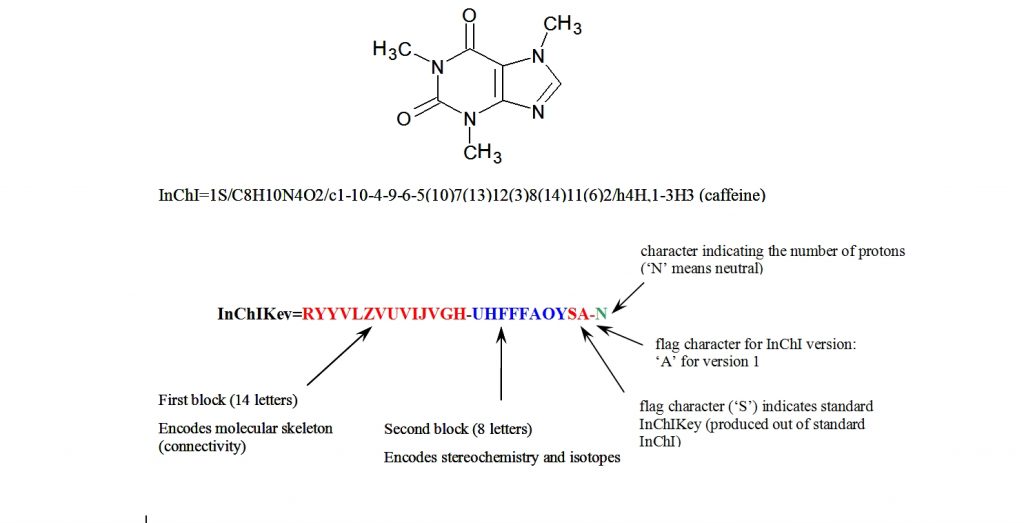
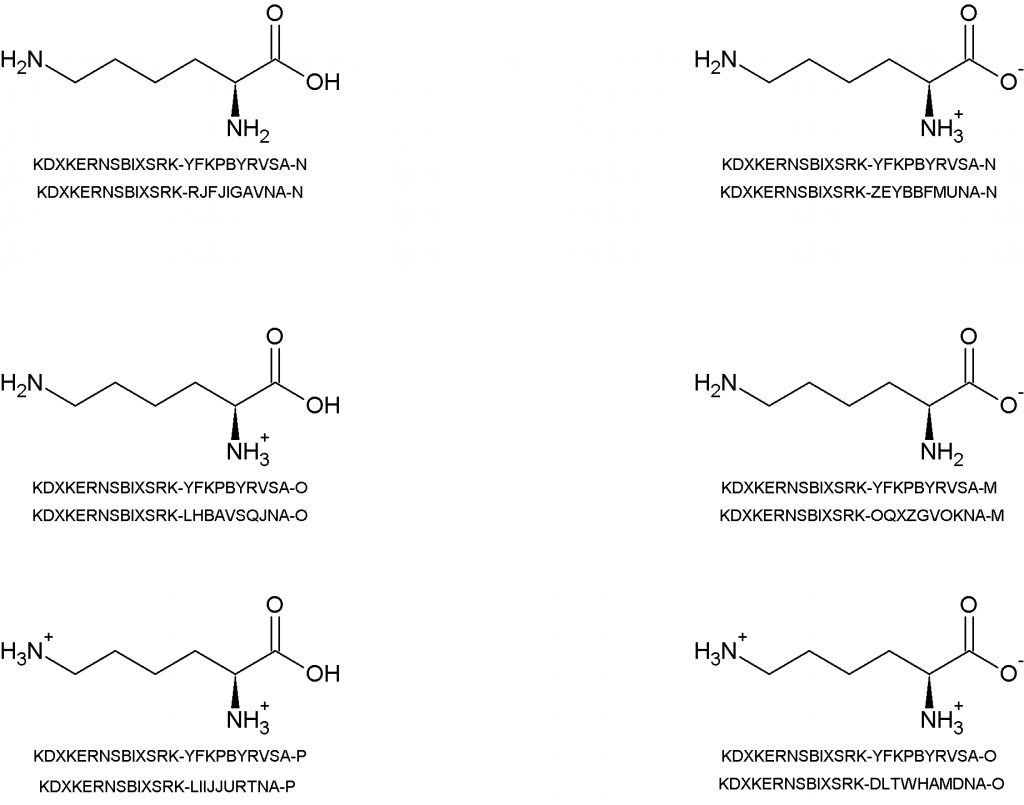
The IUPAC Chemical Identifier or InChI (“pronounced “en-chee”) is a world-wide computer based standard for chemical structure representation created by the collaboration of chemists around the world under the auspices of IUPAC. The InChI format and algorithm are non-proprietary and the software is open source, with ongoing development done by the chemistry community.
![]()
The result of this world-wide collaborative effort has been the development, maintenance, and expansion of the capabilities of the open source, freely available, nonproprietary International Chemical Identifier (InChI), first by NIST and now by the InChI Trust (1), a not‑for‑profit UK charity which is supported by contributions from member organizations.
Over 100 chemical information specialists and computational chemists comprise an internet forum to examine and test the software before each public release; this optimal quality control by a world‑wide user community has led to improvements to and new releases of the software. The reliance on input from many volunteers from around the world enables the project to be staffed by a part-time project director and a programmer.
The usage of InChI is now common enough in chemical structure handling within databases, publications, and by cheminformatics software that it can be considered ubiquitous in these areas. A random and small sample of those who have added InChIs and InChIKeys to their data and information are:
- PubChem – 93 Million structures
- European Biometrics Institute UniChem – 151 million structures
- Royal Society of Chemistry – ChemSpider – 60 million structures
- National Cancer Institute – Chemical Structure Lookup Service – 74 million structures
- ChemNavigator iResearch Library 371 million structures
- Elsevier – Reaxys 29 million structures
- ACS/CAS – Chemical Abstracts Service – over 100 million
The InChI and InChIKey have become essential tools for scientists worldwide, providing a new Common Language for Chemistry. The power of these tools allows chemists and computers to communicate more effectively thereby accelerating the pace of scientific research.